Here I will implement three different variations on gradient descent using logistic regression loss: regular gradient descent, stochastic gradient descent, and stochastic gradient descent with momentum.
With gradient descent, I begin with a random guess for the minimizer of the loss function. At each point, I compute the gradient and take a step (whose size is modulated by the stepping size) in that direction. This updates the new guess for the minimum, and I continue until the gradient is close to the zero vector.
For stochastic gradient descent, I use the same general approach but instead divide the data up into random batches. Additionally, I implemented stochastic gradient descent with momentum, which uses the difference between our current and previous guesses for the momentum update to inform the next update on our guess. This ensures that if we have a good guess for the minimizer, we more quickly head in that direction (and more quickly converge).
Starting with simple 2D data:
from adam import Adam # your source codefrom sklearn.datasets import make_blobsfrom matplotlib import pyplot as pltimport numpy as npnp.seterr(all='ignore') np.random.seed(123)# make the datap_features =3X, y = make_blobs(n_samples =200, n_features = p_features -1, centers = [(-1, -1), (1, 1)])fig = plt.scatter(X[:,0], X[:,1], c = y)xlab = plt.xlabel("Feature 1")ylab = plt.ylabel("Feature 2")
In this case, notice that stochastic gradient descent with momentum converges fastest, then stochastic gradient descent, then regular gradient descent.
As we can see, the separating lines for all algorithm are quite similar.
Altering the Stepping Size
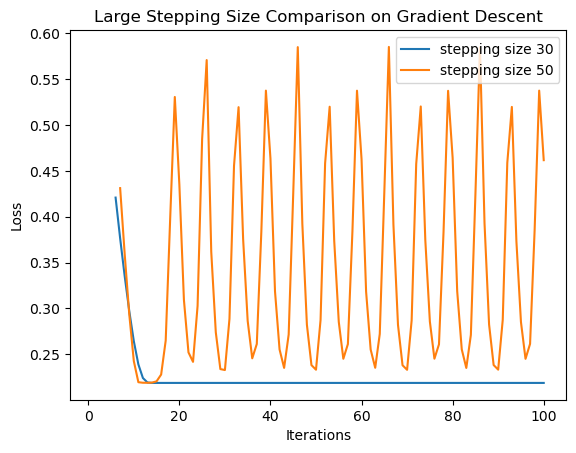
Below is a case I show some larger stepping sizes. It is suprisingly robust, however, as even a large stepping size of 30 yields a reasonable loss. Perhaps the gradient is naturally small.
LR = LogisticRegression()LR.fit(X, y, alpha =30, max_epochs =100)num_steps =len(LR.loss_history)plt.plot(np.arange(num_steps) +1, LR.loss_history, label ="stepping size 30")LR = LogisticRegression()LR.fit(X, y, alpha =50, max_epochs =100)num_steps =len(LR.loss_history)plt.plot(np.arange(num_steps) +1, LR.loss_history, label ="stepping size 50")legend = plt.legend() plt.xlabel('Iterations')plt.ylabel('Loss')plt.title("Large Stepping Size Comparison on Gradient Descent")
Text(0.5, 1.0, 'Large Stepping Size Comparison on Gradient Descent')
As we can see, the loss never converges for a stepping size of 50, as this proves to be too large for proper gradient descent.
Altering the Batch Size
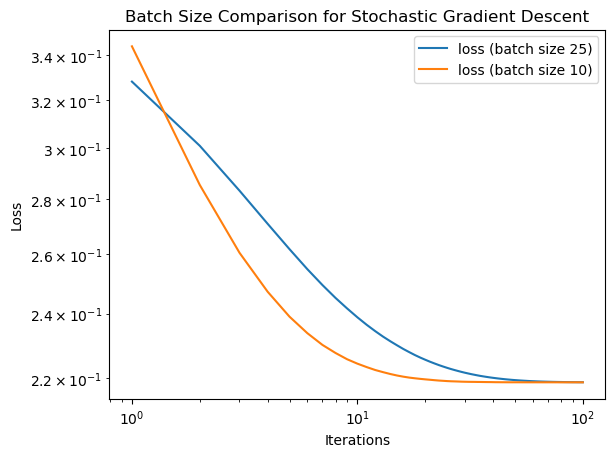
Here I demonstrate that the batch size can affect how quickly stochastic gradient search will converge.
Text(0.5, 1.0, 'Batch Size Comparison for Stochastic Gradient Descent')
As we can see, a smaller batch size allows for a faster convergence, perhaps because the gradient descent more frequently updates the point of the minimum loss.
Gradient Descent in Higher Dimensions
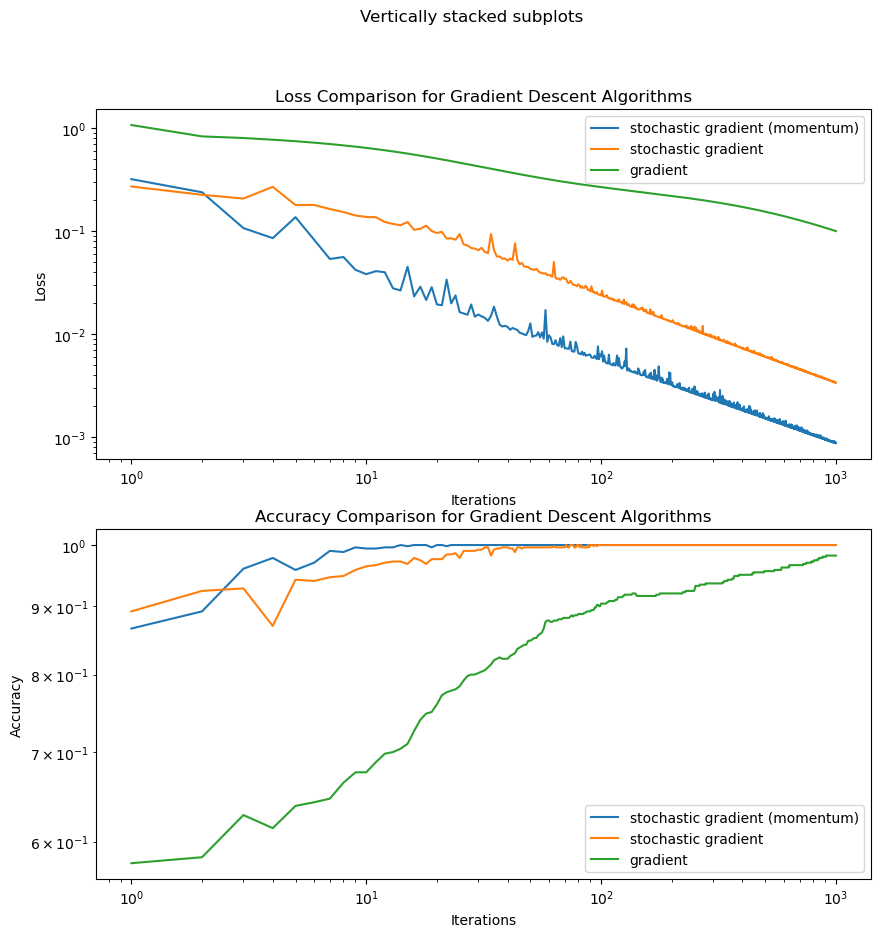
Below I have plotted comparisons of the gradient descent algorithms in 10 dimensions. Notice that the convergence is faster for stochastic gradient with momentum. In fact, all the gradient descent algorithms converge quite quickly.
I initially used random vectors for the centers of the blobs but it seems that the data may be linearly separable (hence the fast convergence). Perhaps in higher dimensions, this method of generating data makes it easier to separate linearly. For this new data set, I randomized a vector to multiply to one data set so they are not as linearly separable.
Stochastic gradient descent with momentum clearly converges the fastest. Stochastic gradient both with and without momentum appear to fluctuate in the loss (probably as a result of the random batches), but both converge faster than regular gradient descent and even reach 100% accuracy.